How to stream to YouTube Live from a Skype call
January 22nd, 2019 | Published in Uncategorized
Last month I helped Ariel Waldman run a YouTube Live stream from McMurdo Station in Antarctica where she answered questions from her Patreon supporters. We believe that this is the first time that anyone has broadcasted live to the internet in this way from Antarctica, because the only supported streaming service at McMurdo is Skype. This post is the documentation for the process I used to make this connection.
You will need a collaborator outside of Antarctica who will relay the Skype call to YouTube Live. If you are that collaborator, you will need the following software and hardware:
- a computer and a high-bandwidth internet connection. The computer will be encoding MPEG4 video in realtime, so it needs to be reasonably modern and powerful. I used a Macbook Pro with a quad-core Intel i7-3.1Ghz, and my home internet connection which is Comcast cable with a 12Mbps upload speed. You can use a Mac or a PC.
- Your own Skype account, and the latest version of the Skype client installed
- A copy of OBS installed
- The OBS NDI plugin installed into OBS
- a YouTube account (or the username and password for YOUR YouTube account)
Set up the Skype client before the call by going to Settings -> Calling -> Advanced and make sure “Allow NDI Usage” is switched on.
Set up the YouTube Live stream before the call by going to YouTube Creator Studio and scheduling a new live event. After the event is created, opt for a “Single-use stream key”, choose “Other encoders” and copy the code given under “Stream Name”. You’ll need it when we configured OBS. Now if you click on “View on watch page”, a new tab will open with the URL that you can distribute to your viewers ahead of the event. It’ll show a placeholder screen until you begin streaming at the time of the event.
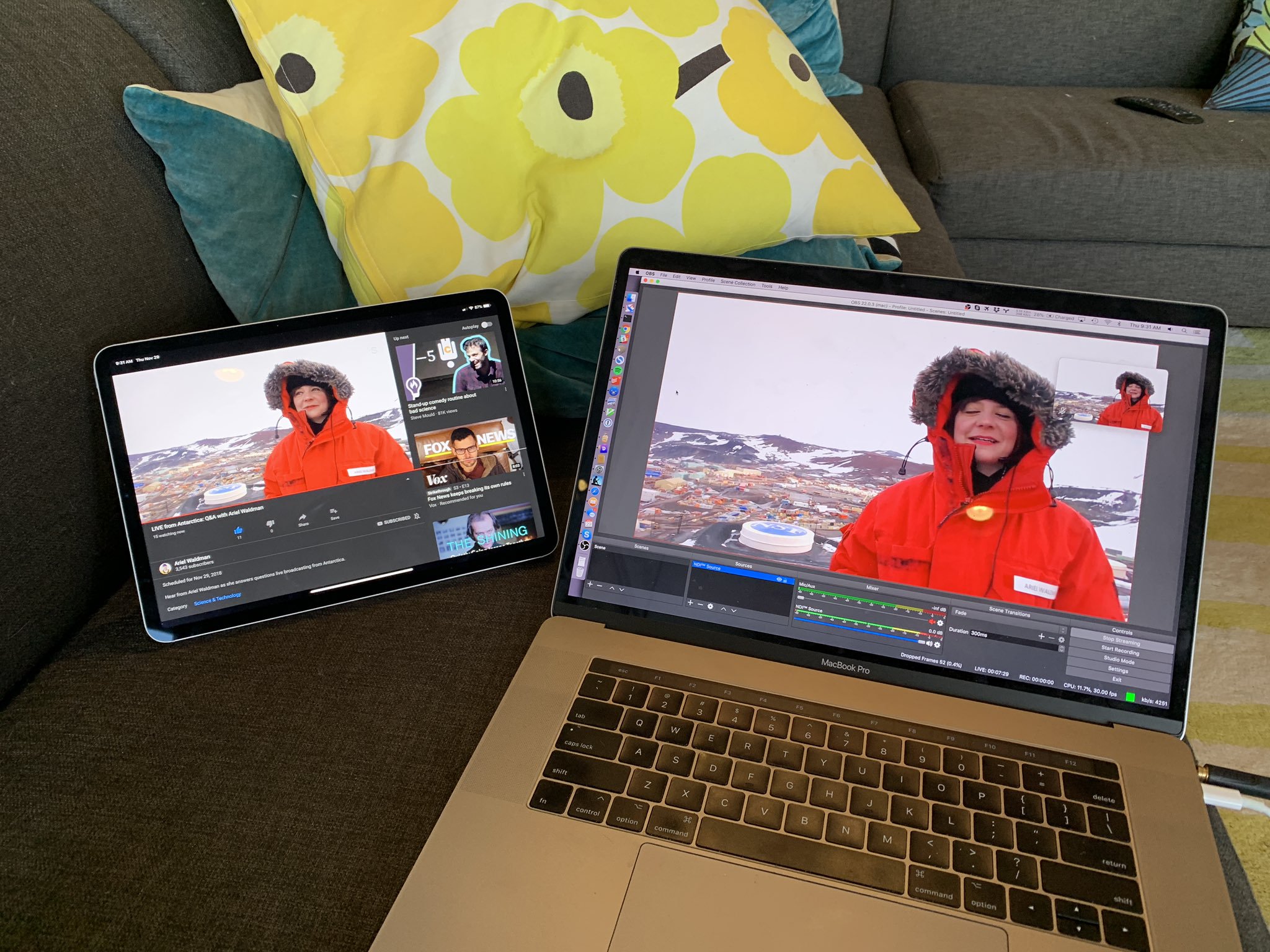
And finally, load up OBS before the call begins. Click the Plus icon at bottom left to add a new Scene. Then click Plus under Sources and add a new “NDI Source”. Just click OK for now to accept the defaults – later we’ll use this to connect with the Skype call and receive the audio and video for streaming. In the Mixer section, drag the slider for Mic/Aux down to zero to ensure that sound from your own laptop microphone won’t get incorporated into the stream.
Now go to OBS Preferences and find the Stream section. Select YouTube as the Service type, and under Stream Key you can paste the YouTube code that you copied earlier when you configured the live stream. On the Output section, enter 4000 as the video bitrate. Under Video select a Base Resolution and an Output Resolution of 1280×720. This is the native Skype client resolution at the time I write this. Finally, right-click on the main area of the OBS window in what is currently a big black box. Under “Transform”, turn on “Fit To Screen”. This will ensure that if Skype resizes the video stream due to a poor connection during the call, it still gets scaled by OBS to fit the full resolution of the YouTube Live video window.
When it’s nearly time for the live stream:
- Ensure your Skype client is running and logged in
- At McMurdo, they should make a video call to your Skype account several minutes before the scheduled live stream
- At your end, ensure that NDI is enabled in Skype and double-click on the NDI Source in OBS to bring up its configuration window. There should now be something listed in the dropdown menu under “Source Name” that mentions Skype. Select this and hit OK, and the black box in the main OBS window should start showing the Skype call live. At the McMurdo end, you’ll see a message telling you that the call may be being recorded.
- Hit “Start Streaming” in OBS and then go to the YouTube Creator Studio in a web browser. Select your event and go to its “Live Control Room”. You should soon see audio and video appear in a preview window there.
- At this point, you will still be able to talk on the Skype call to the person at the McMurdo end. Let them know that you’re ready to put them live, count them down from ten, and hit the button in the YouTube Live Control Room to start the live event.
- When it’s all done, stop the event from the YouTube Live Control Room, stop streaming in OBS, and end the Skype call.
If everything goes smoothly then you’ll be rewarded with a high-quality YouTube Live stream that you can monitor on a second device like a phone or tablet. You should expect that there will be as much as 30 seconds lag behind the Skype stream when viewing the stream this way.




 And to send a message:
And to send a message: