Using Wikipedia and the Yahoo API to give structure to flat lists
September 2nd, 2005 | Published in metadata | 2 Comments
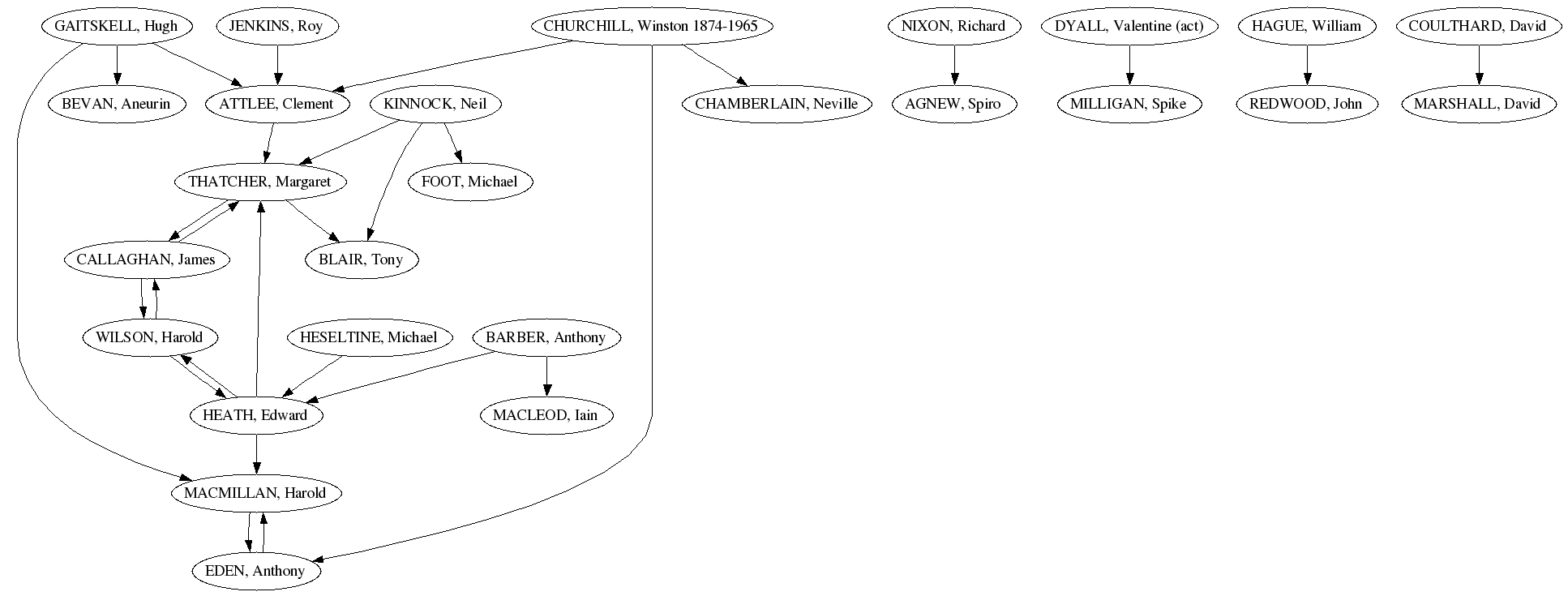
Some of my recent (and final) work at the BBC has involved breathing life into old rolodex-style flat databases of content. With my colleague Tom Coates, I’ve been puzzling over how to take a list of text strings like this:
"AGNEW, Spiro", "ATTLEE, Clement", "BARBER, Anthony", "BEVAN, Aneurin", "BLAIR, Tony", "CALLAGHAN, James", "CHAMBERLAIN, Neville", "CHURCHILL, Winston", "COULTHARD, David", "DYALL, Valentine", "EDEN, Anthony", "FOOT, Michael", "GAITSKELL, Hugh", "HAGUE, William", "HEATH, Edward", "HESELTINE, Michael", "JENKINS, Roy", "KINNOCK, Neil", "MACLEOD, Iain", "MACMILLAN, Harold", "MARSHALL, David", "MILLIGAN, Spike", "NIXON, Richard", "REDWOOD, John", "THATCHER, Margaret", "WILSON, Harold"
and turn it into a network of directed links like this. Hopefully anyone who has a passing knowledge of the history of the British government will agree that it’s a convincing little map, easily usable as a basis for navigation around the concepts attached to the text strings
{kind=link}
We found a pretty neat automated solution, entirely based on public internet resources, that requires no input at our end apart from the text strings above.
The first step is to turn our flat text strings into references to internet resources that we can use to gather judgements about them. For the politics domain (and for a vast variety of others), Wikipedia is an obvious choice. How do we turn “BLAIR, Tony” into https://en.wikipedia.org/wiki/Tony_Blair? The simplest approach, transforming the former string into the latter by regular expression, doesn’t work for all cases, even in this small data set. Note the URL for Anthony Barber, for example. Thankfully, the solution is still simple: we use a search engine. Yahoo’s REST API is far preferable to Google’s SOAP, so we use it to formulate a search for “margaret thatcher” restricted to wikipedia.org and take the top result.
Straight away we’ve added value to our database. With a plausibily-canonical URL for Margaret Thatcher (certainly an inverse functional property in ontology terms), we can use a service like Bloglines Citation Search to gather web zeitgeist around that particular politician.
Wikipedia gives us much more than just an identifier, however. There’s great human-readable information in that resource. Luckily, the Yahoo API has another service that can help machine-agents make sense of human prose. Its Term Extraction service will take a chunk of content and return a short list of ‘significant words or phrases’ from it. Incidentally, you can play with some great visualisations based on this service at tagcloud.com.
If we run the HTML from Thatcher’s wikipedia page through an html-to-text process (perhaps lynx -dump) and then hand the text to the Yahoo service, we get the following:
- margaret thatcher
- baroness thatcher
- woman
- political philosophy
- james callaghan
- figurehead
- government spending
- margaret hilda thatcher
- conservative party
- tony blair
- wikipedia
- wikimedia
- free encyclopedia
- thatcherism
- order of the garter
What’s particularly interesting about this list? It contains some text strings we can relate directly back to members of our original list. So we judge that Margaret Thatcher links to James Callaghan and Tony Blair. Repeat this extraction and correlation process for each member of the list and you get the map we are looking for. While a political journalist might complain about its completeness, it’s an impressive result that comes at zero cost.
What are the implications of this method? Firstly, it shows yet again the value of using existing well-designed URLs as globally-unique and resolvable identifiers for concepts. Simply using a consensus URL as a proxy for a concept increases the chances of correlating your information with that of others on the web. As the method is applicable to any text strings, it could be used with a list of tags attached to a URL or photo on flickr or del.icio.us. While it certainly wouldn’t give results on the every single tag, any result at all is better than none.
Secondly, it’s a great method for adding value to your own data by using external information. It fits well with other emerging thinking on ad-hoc inferencing such as Tom’s How To Build On Bubbleup Folksonomies. Now that tagging and URL-linking are firmly established as viable and accessible tools for distributed correlation and consensus-forming, second-generation techniques such as these can start to take advantage of the resulting network effect. We can aggregate opinion and categorisation up the chain, and across the network, along any axis that makes sense for our problem domain. By using external resources, we can start somewhere in our data, hop up onto the web, take a few steps, and come back down in a different, yet relevant, part of our own database.
November 14th, 2008 at 9:14 pm (#)
Hi Matt, This was a really interesting article and inspired me to look into a few new avenues for our project. I noticed you're coming down to Wellington next year.
We are based here so let me know if you have time on your visit for a beer or a coffee.
Cheeres
Scott
November 14th, 2008 at 9:17 pm (#)
Oh, my email is : scott [at] cloudworkers [.] com